Beyond the Hype: Why Standard RAG based AI is Too Unpredictable for Critical Industrial Procedures
Retrieval-Augmented Generation (RAG) is a leading pattern for boosting AI systems with real-time access to domain knowledge (aka: giving your AI access to a large amount of sources). In standard RAG, an LLM isn’t restricted...
Retrieval-Augmented Generation (RAG) is a leading pattern for boosting AI systems with real-time access to domain knowledge (aka: giving your AI access to a big amount of sources). In standard RAG, an LLM isn’t restricted to its training data; it retrieves external text segments (“chunks”) from a vector database or external knowledge base and conditions its output on them.
For many consumer and enterprise use cases - particularly chatbots and interactive assistants - this provides a massive leap in factual grounding. But that doesn’t mean RAG is suitable “as-is” for environments where consistency, repeatability, and absolute correctness every single time matter.
1. Arbitrary Chunking Breaks Context – and Context Is Everything in Industry
Standard RAG pipelines break documents into fixed-sized chunks based on token (close to character counts). This might be simple to implement, but it often splits sentences, tables, procedures, or even entire logical steps in ways that destroy semantic coherence.
If a vector retriever pulls a chunk representing half of a safety procedure or a fragment of a specification without vital qualifiers, the LLM can generate a plausible-sounding answer that is actually incomplete or incorrect - in technical literature this is linked to semantic context loss.
In critical industrial settings - e.g., safety instructions for a chemical reactor, torque settings for an engine assembly, or calibration steps for a airplane engine - missing or jumbled context isn’t just confusing, it’s dangerous.
In contrast, industrial procedures typically need structured, categorical knowledge with no missing steps - the type that doesn’t lend itself to arbitrary slicing. A system that treats every answer like a statistical best guess risks producing inconsistent outputs from one query to the next.1
2. RAG’s Variability Undermines Determinism and Reproducibility
While core RAG retrieval algorithms can be made deterministic under tightly controlled conditions, real-world industrial deployments are not static systems. In practice, reproducibility degrades as corpora are updated, documents are added or removed, embedding precision changes, or indexes are rebuilt - all of which materially alter retrieval outcomes.
For industrial procedures that must remain invariant across time, system updates, and operational context, this form of systemic variability is unacceptable.2
3. Standard RAG Isn’t Designed to Say “I Don’t Know” with Authority
One of the core weaknesses of current RAG systems is that the generative model frequently produces an answer even when the retrieved information is insufficient or partially misleading. In other words, the model often guesses rather than declines to answer.
And that is because, by design, RAG based systems stop retrieving information once they reach the model's context window limits. At some point, the system effectively says "this is enough." But the very next document it did not retrieve might contain information that contradicts or significantly reframes the initial answer - potentially invalidating it entirely. And the problem is: how would you ever know?
For critical procedures, the right behavior when data is incomplete is not to invent plausible details, but to alert the operator or system that it lacks sufficient information. This is an integrity requirement - and standard RAG doesn’t enforce it.
Systems used in industrial quality assurance or compliance frameworks must adhere to defined correctness barriers; anything less erodes trust and violates governance policies.
4. Deterministic Systems Are the Right Fit for Repeated, High-Assurance Tasks
Deterministic systems, like Yoshu, can incorporate full procedural logic, fail fast when context is absent, and guarantee no ambiguous answers. For industrial processes - where every step may have legal, safety, or quality implications - these guarantees simply can’t be optional.
| Feature | Standard RAG | Yoshu |
| Output repeatability | Low | 100% |
| Handles missing context | Poor | Explicitly |
| Ability to “fail safely” | Limited | Built-in |
| Predictability | Probabilistic | Rule-based |
| Verification & auditability | Hard | Guaranteed |
5. How Yoshu Works
Yoshu is built from the ground up for deterministic industrial procedures, not probabilistic guesswork. The system is designed to take unstructured knowledge - like manuals, SOPs, and operator notes - and turn it into a structured, verifiable workflow that guarantees consistent outputs. Here’s how the process unfolds:
We Structure Unstructured Data
Raw documents, PDFs, spreadsheets, machine and operator logs are first converted into augmented assets®. Yoshu breaks information down semantically rather than arbitrarily, capturing complete procedural steps, conditional logic, and safety constraints. This ensures that context is never lost, and every detail relevant to execution is preserved.
Ingesting into Datasets
These structured assets are ingested into Yoshu’s datasets, forming a single source of truth. Unlike traditional RAG systems, which rely on probabilistic retrieval from loosely indexed text chunks, Yoshu links every instruction, calculation, and parameter to its verified source. The dataset is continuously versioned, auditable, and ready for workflow deployment.
Workflow Layer Built by Experts
Domain experts overlay operational workflows on top of these datasets. Every task, decision point, and exception is explicitly encoded. This step ensures that best practices, regulatory compliance, and safety requirements are embedded in the system, making it impossible for the AI models to generate outputs outside these boundaries.
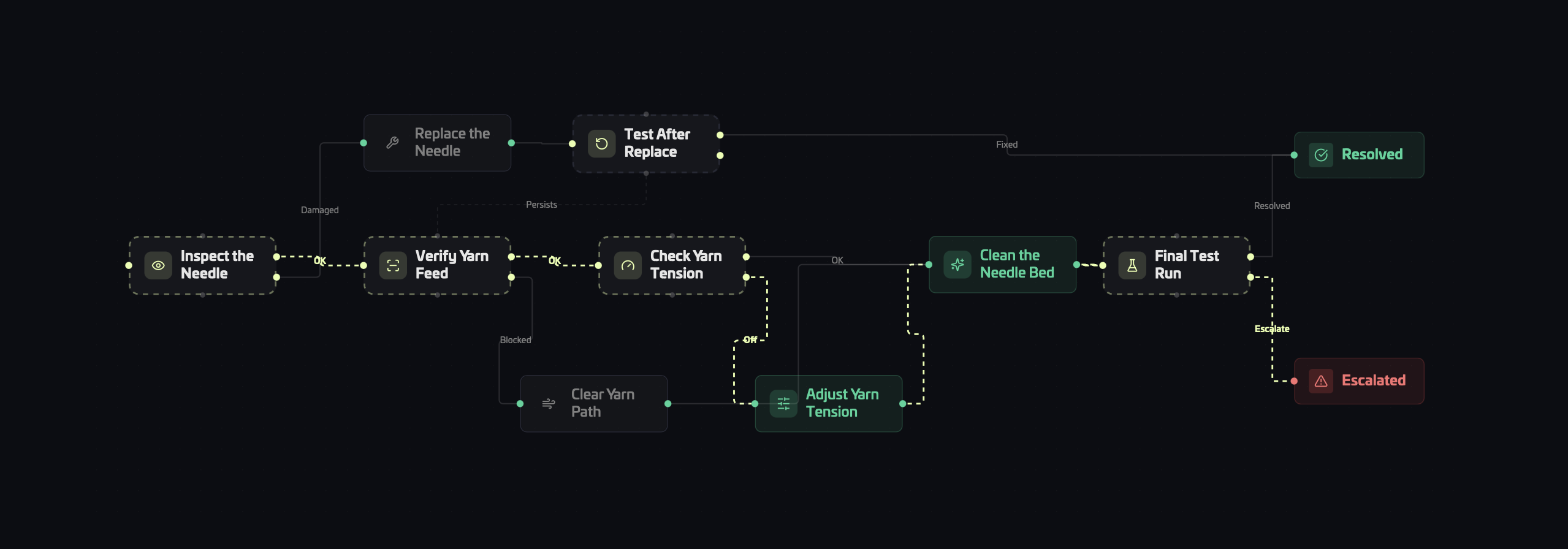
Deterministic Execution
When operators interact with Yoshu, calculations and data retrieval come directly from the verified database. The LLM is only called for displaying results or generating outputs in human-readable form, never to invent or guess. This guarantees 100% repeatability and accuracy, even as datasets evolve or the AI is updated.
Continuous Learning without Compromising Safety
Yoshu tracks operator decisions in real time. If an operator deviates from a prescribed step, the system prompts them to verify why, logs the reasoning, and routes it for expert review. Once validated, these insights can update workflows globally -after expert validation-, turning individual expertise into institutional knowledge without risking safety or compliance.
Auditability and Compliance Built In
Every step is logged, timestamped, and traceable. Yoshu is designed to pass internal audits and regulatory inspections, providing full transparency into why a given procedure was executed and what data it was based on. This turns operational knowledge into a verifiable, fail-safe system - something standard RAG pipelines cannot do by nature.
Takeaway: Standard AI enriched with RAG has undeniable value, but there is a time and a place and that is not designed for mission-critical industrial procedures where incorrect outputs have material consequences. At Yoshu, we believe the future of industrial AI must be: deterministic, verifiable, and fail-safe. In industrial environments, “close enough” isnt safe - it’s a liability. That’s why the top organizations working in the most regulated sectors trust Yoshu to deliver. Don’t get left behind in the the future of industrial AI - come build the future of industrial expertise.